DDD (please don't)

TL;DR
Dependencies are inevitable and everywhere, and they’re the cause of many of your problems. Learn to identify and deal with them. Your project is probably a failure if you have not reduced them or made them more manageable.
What’s this?
In a previous post I argued that we focus too much on fruitless bureaucratic nonsense, and that we should spend our time on more useful things. One way to achieve this is to view problems through the lens of dependencies.
I want to give you a sense of what they are, where they are, and how to get work done in their presence.
Note that none of this is specific to software or IT projects, even though my examples are mostly from that world. This is a useful way to view any problem-solving.
Dependencies
Let me define what I mean by a dependency, and then I’ll talk about how dependencies combine.
What is a dependency?
A circular definition is: When something depends on something else.
A more useful definition is:
If thing A doesn’t work in the absence of thing B, then A depends on B.
UML-style, I’ll show a dependency as a dotted arrow. A depends on B. Something depends on Something else.
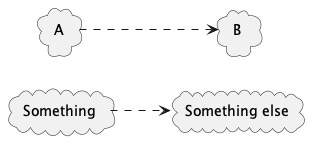
There are three important implications:
Changes to A do not affect B (B doesn’t know that A exists).
Changes to B may affect A (depending on the exact change).
Removal of B does affect A (by the definition of a dependency).
Dependencies compose
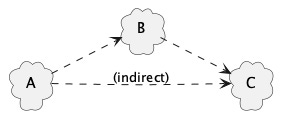
If A depends on B, and B depends on C, then A depends (indirectly) on C (since B stops working if C stops working and A stops working if B stops working).
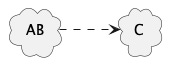
In this isolated sense, it’s useful to know that A and B can be replaced with something else (I’ll call it AB here) that performs the role of A and B, without affecting C.
Dependency complexity compounds exponentially
A depending on B and C can be more than twice as complex to deal with than A depending on B or C alone.

A and B depending on C can be more than twice as complex to deal with than A or B alone depending on C.

If you don’t realise this (or don’t want to admit it) your project will be much slower, much more expensive, and much more difficult than estimated, which is exactly what happens all the time. The larger the change, the worse it gets too.
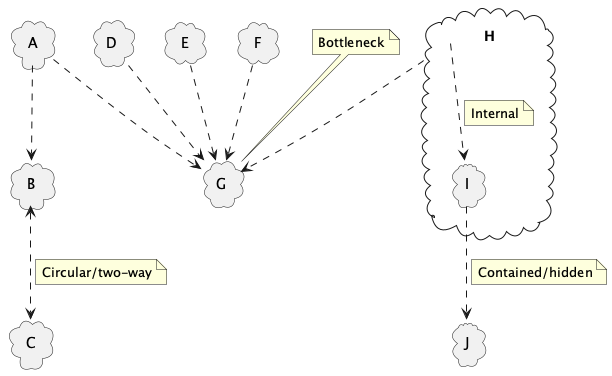
Reality is messy
Rather than neat one-way dependencies, real-world situations often have a large number of tricky dependencies. This is a, sometimes the, major reason why making meaningful changes is difficult.
Examples:
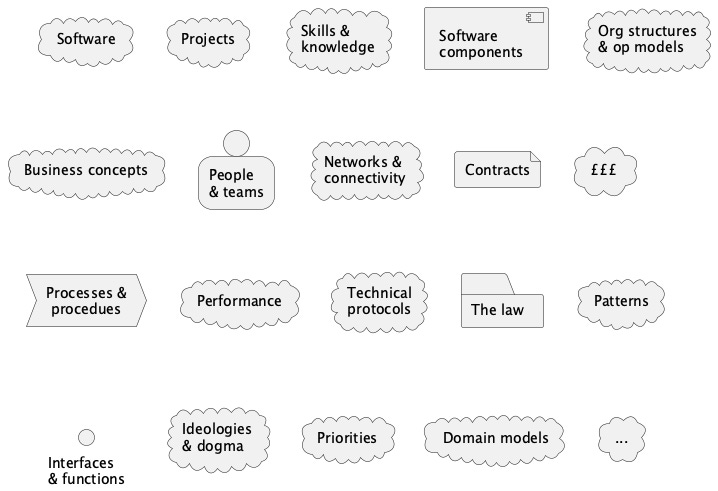
It’s not just software
Real-world dependencies exist between different kinds of things, at different abstraction levels. Software is just a small part of this, and often the easiest to deal with. Too much focus on software, and software dependencies, distracts from bigger and more important problems.
Examples:
Internal/implicit and external/explicit
A dependency on an internal/implicit thing (such as an un-written assumption) is just as real as a dependency on an external/explicit thing (such as a component implementing the assumption), and can be just as hard, or harder, to deal with.
Example: Components A and B both containing a business concept in the same way (they make the same assumptions about it) is functionally the same as an external/explicit dependency. This is true because, in both cases, if the concept changes sufficiently, both A and B stop working.
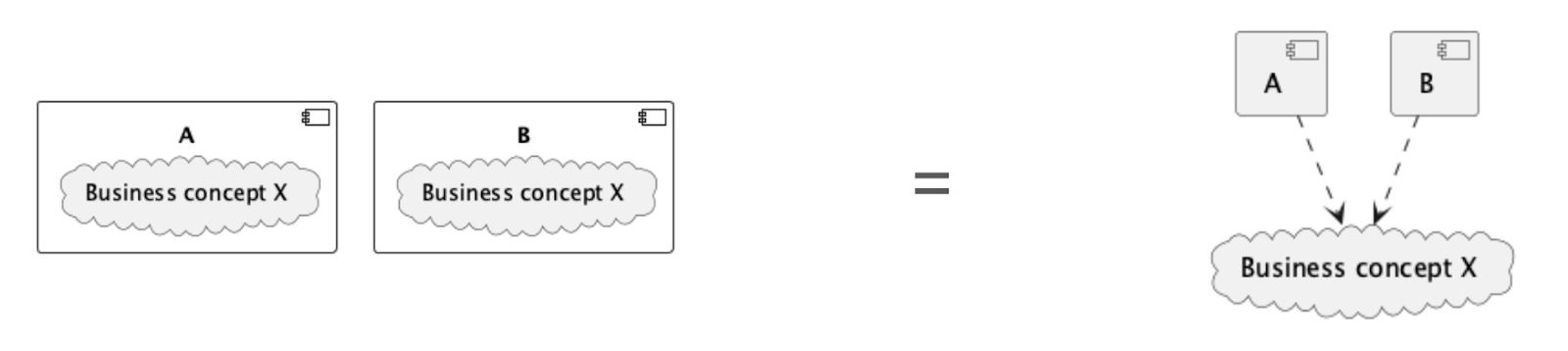
Keep this in mind when you’re tempted to break things down into smaller bits. A large number of teams refactoring an even larger number of microservices to synchronise some shared concept, can be much harder than doing it in the monolith they replaced.
Specificity; abstraction level
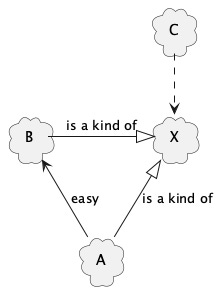
It is easier to swap out a thing for another thing of the same kind, than it is to swap out a thing for a different kind of thing.
Example of an easy change: A is an X kind of thing, and C requires an X kind of thing to work (but doesn’t care which X kind of thing). Since B is also an X kind of thing, it can replace A fairly easily, sometimes even without C knowing about it).
Example of a hard change: C depends specifically on A. Since B is not the same kind of thing as A, it can not easily replace A, and you are forced to make changes to C as well.
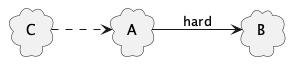
The lesson here is that the more abstract you can make your dependencies, the more resilient and flexible you are. This requires you to think more about kinds of things than things - a habit that needs to be trained. There is a limit to this, of course, and you can over-generalise and end up with abstractions that are too broad and therefore not useful. Doing this well is definitely more art than science.
Note that humans are much better at abstractions than machines or software. Keep that in mind when, say, you are converting some business process into software. The human version might be slow and inconsistent, but it deals with all kinds of ambiguities and not-seen-before cases without a system change (as long as the humans involved are capable and empowered). When turning this into software, there is a tendency to disambiguate too much and try to predict and deal with all edge cases, which makes your dependencies too specific. Apart from being futile (there is always some case you didn’t consider or couldn’t predict), project returns diminish rapidly when you reach this stage, and the resulting software becomes unmaintainable much earlier. Let humans and machines each do what they’re best at.
Making changes in the presence of dependencies
Now that we have an idea of what dependencies are, let’s look at how we deal with them when solving problems. It turns out there are only 4 ways to deal with making changes to a thing with an incoming dependency. (Outgoing dependencies are not a problem, by the definition.)
Abstract problem
We illustrate this with an abstract problem:
A depends on B
We want to make changes to B
The change will break the dependency
What do we do with the broken dependency?
I will use ‘ (prime) to indicate a change, so if A changes it becomes A’, if B changes it becomes B’, etc.
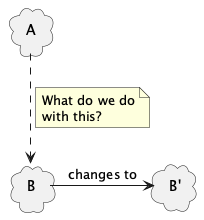
I reiterate, this is not just about software. A and B above can be teams, processes, ideas, laws, concepts, etc. and not just functions, microservices, APIs, databases, and so on.
A real-world problem with multiple dependencies must be broken down into this level to actually fix, and you are doing it, whether you realise it or not. There is no way around this, but it frequently gets ignored (mostly through literal ignorance of it) and most projects don’t have any specific/explicit plans at this level. In the end, reality always forces you to pay attention.
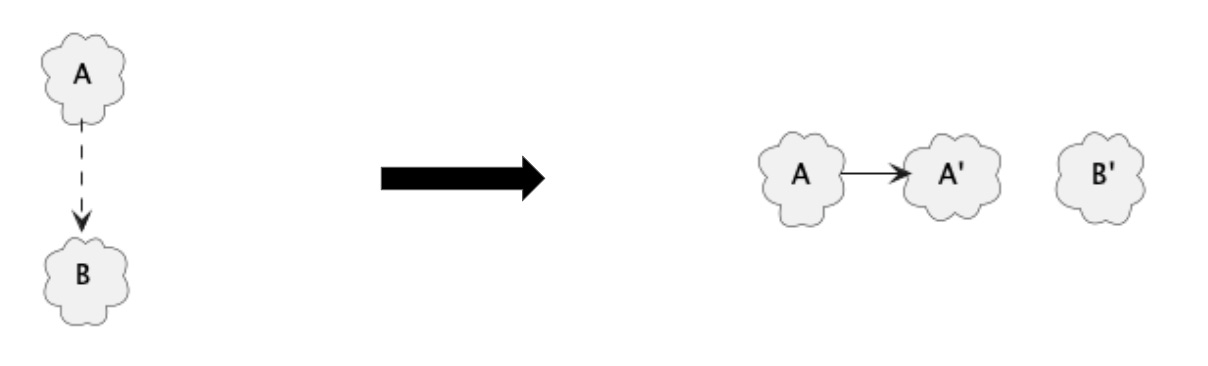
Abstract solution 1: Remove dependency
It’s possible that A didn’t have to depend on B in the first place, so we can just factor out the dependency. This requires a change in A as well as B.
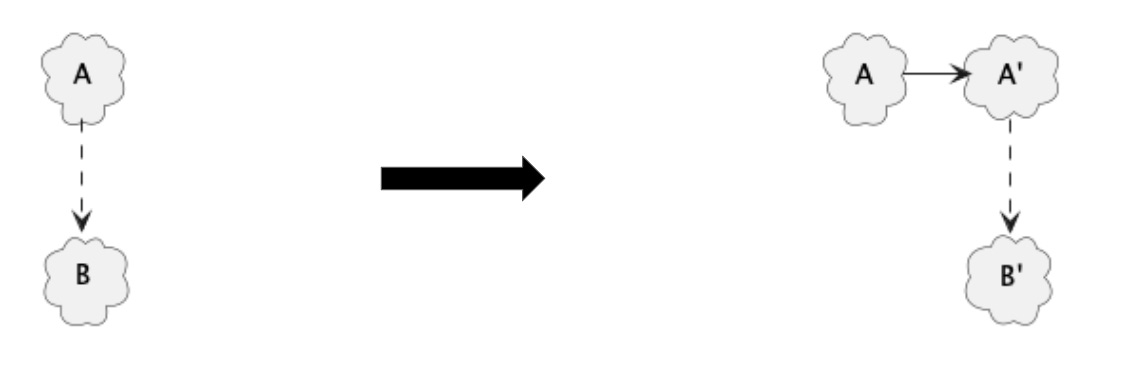
Abstract solution 2: Keep dependency, change A
If we need to keep the dependency, we have two options. The first is to make A depend on B’ instead of B. This requires a change in A as well as B.
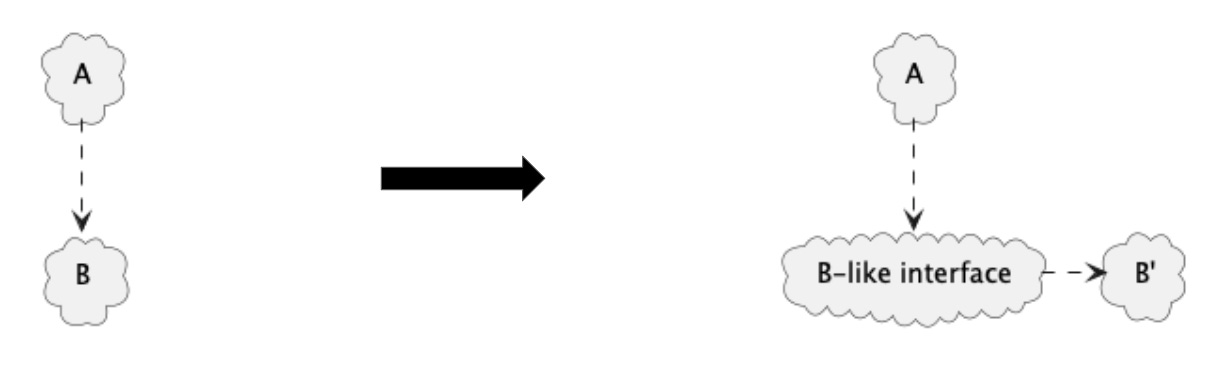
Abstract solution 3: Keep dependency, don’t change A
The second option for keeping the dependency is to create a new thing that looks like B and have that depend on B’. This does not require a change in A, but requires a new thing to take B’s place.
Abstract solution 4: Complete redesign
It may be appropriate to not only make changes to B, but to absorb the function of A and completely replace A and B with something new (X).

Which lane are you (honestly) in?
The amount of control you have over the entire situation (all the dependencies) determines how quickly, and in how many steps, you can go from the current state to the final state.
The fast lane
When you’re in complete control, you can go as fast as you like in as few steps as you like. An extreme (and uncommon) example is making internal changes to well-understood, well-tested software that’s actively maintained by a single, small, capable team in a low-bureaucracy environment. This could be done with a single deployment that can be rolled back if necessary.
The slow lane
When you have less control, you have to go slower and take smaller steps. An extreme (and very common) example is making changes to multiple, inter-dependent components, each of which owned by a different team with a poor understanding and low skill, in a bureaucratic, dysfunctional organisation. (My entire working life.)
Unfortunately, wishful/utopian thinking does not add speed.
How to go slow
If you’re in the slow lane (and you almost always are when you’re solving the hard problems), you have to deal with dependencies one-by-one and you likely have to make things worse before they get better, for example by temporarily creating even more dependencies.
The general theme is:
Build a new thing, but keep the old thing around.
Carefully, move things from the old thing to the new thing, one at a time. Move them back if it doesn’t work and fix the problem.
Only when the old thing is no longer used do we get rid of it.
This can be very frustrating and always takes much longer, and costs more, than initial impressions (and business cases) indicate. It requires long-term funding and backing, and patience.
If it’s taken you 30 years to gain 100lbs, you’re not going to lose the fat in 6 weeks, or even 6 months, but you might do it in 6 years. Problems in large organisations have less favourable odds.
A more realistic problem
Let’s make our abstract problem a tiny bit more realistic (but still nothing approaching most real-world problems). A and B are managed by different teams who have lots of other things to do and not enough money to do them. The technology is antiquated and poorly understood. Both A and B have users, sometimes the same ones. We’re clearly in the slow lane.
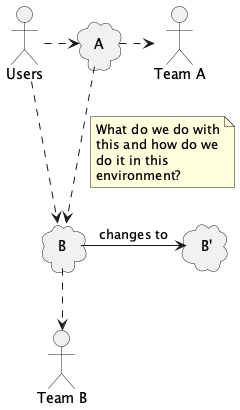
Note that A depending on B implies that Team A depends on Team B and that some users depend on both teams. These are much more difficult dependencies to deal with than the technology dependencies between A and B. If you’re only planning for the technology changes, you’re greatly underestimating the difficulty.
Now let’s look at possible ways in which we can use the 4 abstract solutions to deal with this in the slow lane. The details of the steps and diagrams below are not important, but they illustrate that when you’re in the slow lane, even a simple problem can not be solved quickly.
Solution 1: Remove dependency
Team A introduces A’ and tests it in isolation
Team A deploys A’ into production and runs it in parallel with A. Users are still using A.
Users of A switch over to using A’. Users of B continue using B.
Team A decommissions A

Solution 2: Change A
Team B introduces B’ and tests it in isolation
Team B deploys B’ into production and runs it in parallel with B
Users of B switch to using B’. Users of A still use A.
Team A introduces A’ and tests it in isolation
Team A deploys A’ into production and runs it in parallel with A
Users of A switch to using A’
Team A decommissions A
Team B decommissions B

Solution 3: Don’t change A
Team B introduces Bi (a B-like interface) and tests it in isolation
Team B deploys Bi into production in front of B.
Team B introduces B’ and tests it in isolation
Team B deploys B’ into production and runs it in parallel with B (via Bi)
Users of B switch to B’
Team B decommissions B

Solution 4: Complete redesign
Team X (new team) introduces X and tests it in isolation
Team X deploys X into production and Teams B and X work together to run B and X in parallel
Users of B switch to using X
Teams A and X work together to run A and X in parallel
Users of A switch to using X
Team A decommissions A
Team B decommissions B

How is this supposed to help?
Richard Feynman famously said: “The first principle is that you must not fool yourself – and you are the easiest person to fool.” Thinking about dependencies can help you avoid falling for your own marketing. Below are some real-world examples where you can apply this.
Planning a large-scale transformation for a corporate or government client?
Have you any idea of the scale of the dependencies? Do your plans assume that the problem is linear or exponential? Is this even a sensible project to attempt?
Building a digital platform?
Will it reduce dependencies overall, or is the platform yet another thing in the organisation’s arsenal, i.e. more dependencies? This may make things (temporarily) more pleasant inside the platform bubble, but is this the most important thing to do?
Breaking a monolith down into microservices?
What does having lots of little things looked after by lots of people do to dependencies overall? How will this evolve over time? At what stage will your microservices be as difficult to manage as the monolith?
Modernising the legacy estate onto the cloud?
Assuming it’s even realistic, have you considered the side-effects of having everything depend on not just a single cloud provider, but all the ideas that come with cloud thinking? If you achieve this, all your eggs will be in one basket.
Automating a business process?
Are the machines you’re putting in place as flexible as the humans they’re replacing? Can the machines deal with dependencies on kinds of things as well as the humans?
Putting together a team?
Every extra person increases dependencies exponentially, and the more roles you have, the worse this gets (people who do the same job communicate better than people who do different jobs). All of this can easily outweigh the supposed benefits these people and roles bring. Do you really need business analysts, cloud consultants, content designers, data engineers, delivery leads, integration specialists, operability engineers, product owners, QA engineers, security engineers, service designers, tech leads, technical architects, technical delivery managers, UX designers and user researchers? I genuinely don’t know what half of these are, and the rest we can often do without.
This sounds great. Let’s package and sell it!
Please don’t. As soon as this becomes a monstrosity like dependency-driven development (DDD, D3, Triple-D), the bureaucrats have won and the utility will have been diluted away.
This can never be a template, but it can be a useful way of thinking.